Quand on parle d’éco-conception graphique, on finit toujours par se heurter à un sujet très concret : combien d’encre met-on réellement sur une surface ? Sur du packaging, l’enjeu est donc double : d’une part, il faut composer avec des contraintes techniques telles que le séchage, la surcharge ou les procédés. D’autre part, s’ajoutent désormais des objectifs liés à la sobriété et à la réduction de l’empreinte environnementale.
Dans le guide fourni par CITEO au sujet de l’éco-encrage, le “taux d’encrage” est défini comme la somme des pourcentages de couverture des encres (CMJN et/ou tons directs) sur un échantillon donné.
C’est une base utile. En revanche, la question centrale reste entière : comment le mesurer de manière fiable et reproductible sur un document complet ?
Constat 1 : certains outils semblent difficiles à trouver aujourd’hui
Le guide cite notamment un outil lié à Diadeis. De mon côté, au moment d’écrire ces lignes, je n’ai pas trouvé de moyen d’y accéder / de le retrouver opérationnel (si vous l’avez, je prends l’info 😊). Plutôt que de dépendre d’un outil inaccessible, j’ai cherché une méthode reproductible, documentée et automatisable, basée sur des briques standard.
Constat 2 : la mesure “en un point” n’est pas une mesure globale
L’autre approche souvent proposée consiste à mesurer le taux d’encrage à un endroit précis (avec des outils de type pipette, aperçu séparations, ou lecture d’un point). Le guide présente d’ailleurs ce type de démarche via des outils courants (Adobe Photoshop), en illustrant une lecture ponctuelle.
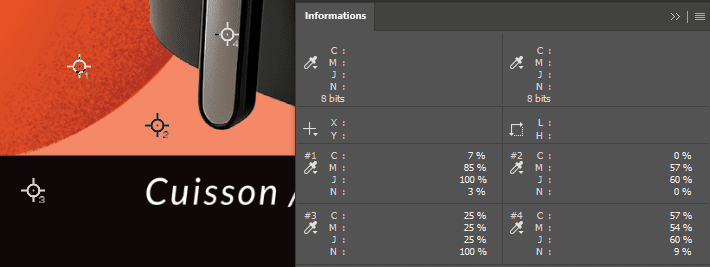
Le souci n’est pas que cette mesure soit “fausse”. Le souci est qu’elle répond à une autre question.
- Une mesure au point répond à : “à cet endroit, quelle est la couverture CMJN/spot ?”
- Une mesure globale répond à : “sur toute la surface du document, quelle quantité d’encre est demandée en moyenne ?”
Et ce glissement est important : un packaging n’est pas uniforme. Entre le fond, les images, les textes, les pictos, les codes-barres… une mesure ponctuelle peut être très différente de la réalité moyenne du document.
Ce qui manque souvent : la mesure globale “par couche”
Là où je pense qu’il manque une marche, c’est l’idée suivante :
mesurer pour chaque encre (CMJN + tons directs) la couverture moyenne sur l’ensemble de la surface, puis en déduire un indicateur global.
C’est particulièrement important en packaging parce qu’il y a fréquemment :
- des tons directs (Pantone, blanc de soutien, vernis, …)
- et ces couches peuvent peser très lourd dans l’encrage global
Si on ne mesure que CMJN, on peut sous-estimer la charge d’encrage de façon significative.
Une proposition constructive : une mesure globale, reproductible, indépendante du RIP imprimeur
L’objectif ici n’est pas de “remplacer” les méthodes existantes, mais de proposer un complément plus mesurable, surtout si on veut comparer des versions de design (V1 vs V2, avant/après optimisation).
L’idée en une phrase
- On transforme le PDF en séparations contone (ton continu) : une image par encre, sans trame.
- On calcule la moyenne de chaque séparation → couverture moyenne de l’encre.
- On somme les couvertures moyennes → TAC moyen (Total Area Coverage moyen).
Le TAC (Total Area Coverage) correspond à la somme des couvertures des encres superposées. Le guide définit d’ailleurs le taux d’encrage comme une somme de couvertures, ce qui rejoint naturellement cette logique, à condition de la faire sur toute la surface plutôt qu’en un point.
Méthode décomposée en étapes
Étape 1 — Partir d’un PDF print final
PDF/X-4 ou équivalent : c’est le document prêt-à-imprimer.
Étape 2 — Rasteriser en séparations contone
On utilise Ghostscript (une brique open-source) pour générer :
- une image par encre (CMJN + tons directs)
- en niveaux de gris (ton continu), avant tramage
En pratique, cela produit des fichiers du type :
separations_1(Cyan).tifseparations_1(PANTONE 485 C).tif- etc.
À cette étape, cela revient au même d’ouvrir le PDF dans Photoshop et d’enregistrer chaque couche séparément.
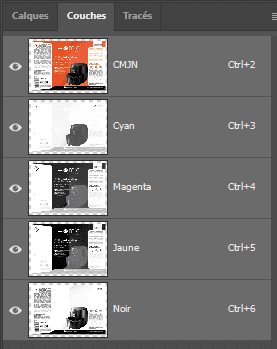
Étape 3 — Calculer la couverture moyenne par encre
Chaque séparation est une “carte” de l’encre :
- 0% = pas d’encre
- 100% = encre pleine
On calcule la moyenne de l’image :
- Couverture moyenne (%) = moyenne(pixel) / max(pixel) × 100
Étape 4 — Calculer un indicateur global
Pour une page :
- TAC moyen = C + M + J + N + Spots
Cela donne un chiffre simple qui permet :
- de comparer deux versions,
- d’objectiver une optimisation,
Automatisation : du protocole au programme
Afin de mettre en place rapidement et facilement cette logique, nous allons utiliser un ensemble d’outils et langages multiplateforme (et avec la formidable aide de ChatGPT 🤫).
Ghostscript
Ghostscript est un interpréteur open-source de formats graphiques standard (PDF, PostScript, EPS).
Dans ce projet, il est utilisé comme un véritable moteur de prépresse : il transforme un PDF en séparations couleur en ton continu (une image par encre, sans tramage). C’est cette étape qui permet de passer d’un document vectoriel abstrait à des données mesurables, exploitables pour un calcul objectif du taux d’encrage.
ImageMagick
ImageMagick est une suite d’outils open-source dédiée à la manipulation et à l’analyse d’images.
Il est utilisé ici principalement comme outil de contrôle et de diagnostic : ouverture des séparations, inspection des valeurs min/max/moyenne, vérification visuelle du contenu des couches. Il permet de valider rapidement que les images générées sont cohérentes avant toute analyse automatisée.
Python
Python est un langage de programmation open-source orienté lisibilité et prototypage rapide.
Il sert ici de “colle” entre les différents outils : orchestration de Ghostscript, lecture des images, calcul des indicateurs, et export des résultats sous forme de tableau (CSV). L’intérêt principal est la reproductibilité : une fois le script validé, l’analyse peut être rejouée à l’identique sur n’importe quel document.
Bibliothèques Python utilisées
Pillow
Pillow est une bibliothèque de lecture et de traitement d’images. Elle permet d’ouvrir les fichiers TIFF générés par Ghostscript et d’accéder directement aux valeurs de pixels.
NumPy
NumPy est une bibliothèque de calcul numérique. Elle est utilisée pour manipuler les images sous forme de tableaux et calculer des statistiques simples (moyenne, min, max) de manière fiable et performante.
Pandas
Pandas est une bibliothèque de manipulation de données tabulaires. Elle sert à structurer les résultats (par page et par encre) et à produire un fichier CSV facilement exploitable dans Excel, LibreOffice ou des outils de visualisation comme Power BI.
import argparse
import subprocess
import tempfile
import os
import re
from pathlib import Path
import numpy as np
import pandas as pd
from PIL import Image
def trouverGhostscript():
"""
Retourne le nom du binaire Ghostscript selon l'OS.
- Windows : gswin64c.exe
- Linux/Mac : gs
"""
if os.name == "nt":
return "gswin64c"
return "gs"
def executerGhostscript(cheminPdf, resolutionDpi, dossierSortie):
"""
Lance Ghostscript pour générer les séparations contone.
Paramètres :
- cheminPdf : PDF d'entrée
- resolutionDpi : résolution de rasterisation
- dossierSortie : dossier temporaire de sortie
"""
gs = trouverGhostscript()
# Pattern de sortie :
# %d = numéro de page
# Ghostscript ajoutera (NomEncre) automatiquement
sortie = str(dossierSortie / "separations_%d.tif")
commande = [
gs,
# Sécurité : empêche l'exécution de code dangereux dans le PDF
"-dSAFER",
# Mode batch : quitte automatiquement après traitement
"-dBATCH",
# Pas de pause entre les pages
"-dNOPAUSE",
# Device spécial : génère une image par séparation couleur
"-sDEVICE=tiffsep",
# Résolution de travail (DPI)
# Plus c'est élevé, plus la mesure est précise (au prix du temps)
f"-r{resolutionDpi}",
# Fichier de sortie (pattern)
f"-sOutputFile={sortie}",
# PDF source
str(cheminPdf)
]
subprocess.run(commande, check=True)
def calculerCouverture(cheminTiff, noInvert):
"""
Calcule la couverture moyenne (%) d'une séparation.
Par défaut (logique Ghostscript) :
- noir = encre
- blanc = pas d'encre
Donc :
couverture = (1 - moyenne_normalisée) * 100
"""
image = Image.open(cheminTiff).convert("L")
pixels = np.array(image)
# Valeur maximale théorique du format (255 en 8 bits, 65535 en 16 bits)
maxTheorique = np.iinfo(pixels.dtype).max
# Moyenne normalisée entre 0 et 1
moyenne = pixels.mean() / maxTheorique
# Contrôle qualité : fond non nul (séparation polluée)
if pixels.min() > 0:
print("⚠️ Attention : fond non nul détecté dans", cheminTiff.name)
# Par défaut : inversion (noir = encre)
if noInvert:
# Mode debug : blanc = encre
couverture = moyenne * 100.0
else:
# Mode normal : noir = encre
couverture = (1.0 - moyenne) * 100.0
return float(couverture)
def analyserSeparations(dossier, noInvert):
"""
Analyse toutes les séparations générées par Ghostscript.
Retourne un DataFrame pandas.
"""
# Regex pour extraire :
# separations_1(Cyan).tif → page=1, encre=Cyan
motif = re.compile(r"separations_(\d+)\((.+)\)\.tif")
resultats = {}
for fichier in dossier.glob("separations_*.tif"):
match = motif.match(fichier.name)
if not match:
continue
page = int(match.group(1))
encre = match.group(2)
couverture = calculerCouverture(fichier, noInvert)
if page not in resultats:
resultats[page] = {}
resultats[page][encre] = couverture
# Construction du tableau final
lignes = []
for page, encres in sorted(resultats.items()):
for encre, valeur in sorted(encres.items()):
lignes.append({
"Page": page,
"Encre": encre,
"Couverture_%": round(valeur, 2)
})
# TAC moyen = somme de toutes les encres
tac = sum(encres.values())
lignes.append({
"Page": page,
"Encre": "TAC_MOYEN",
"Couverture_%": round(tac, 2)
})
return pd.DataFrame(lignes)
def main():
"""
Point d'entrée CLI.
"""
parser = argparse.ArgumentParser(
description="Analyse du taux d'encrage contone depuis un PDF (CMJN + tons directs)"
)
# PDF source
parser.add_argument(
"-f", "--fichier",
required=True,
help="PDF à analyser"
)
# Résolution de rasterisation
parser.add_argument(
"-r", "--resolution",
type=int,
default=600,
help="Résolution DPI (défaut 600)"
)
# Option debug : désactive l'inversion
parser.add_argument(
"--no-invert",
action="store_true",
help="Désactive l'inversion (rarement utile, debug seulement)"
)
args = parser.parse_args()
cheminPdf = Path(args.fichier).resolve()
if not cheminPdf.exists():
raise FileNotFoundError("PDF introuvable")
# Dossier temporaire auto-nettoyé
with tempfile.TemporaryDirectory() as tmp:
dossierTmp = Path(tmp)
print("Rasterisation via Ghostscript...")
executerGhostscript(cheminPdf, args.resolution, dossierTmp)
print("Analyse des séparations...")
df = analyserSeparations(dossierTmp, noInvert=args.no_invert)
# Nom du CSV basé sur le PDF
nomCsv = f"couverture_encres_{cheminPdf.stem}.csv"
df.to_csv(nomCsv, index=False)
print("\nRésultats :")
print(df)
print(f"\nCSV généré : {nomCsv}")
if __name__ == "__main__":
main()
Ensuite, il suffit de se servir de la ligne de commande pour appeler le script et fournir en paramètre le fichier et la résolution souhaitée pour analyser avec plus ou moins de finesse le TAC moyen de toutes les encres.
python analyse_encrage.py -f mon_packaging.pdf -r 600Dans cet exemple, j’utilise 600dpi en résolution de conversion, le but est d’avoir un bon compromis entre la finesse des détails vectoriels (typographies, filets) tout en gardant une valeur proche de la résolution des images et en gardant un temps de calcul raisonnable.
| Type | Résolution courante |
|---|---|
| Web | 7296 dpi/ppp |
| Photo | 300 dpi/ppp |
| Vecteur/Typographie/Aplat | 2540 dpi/ppp |
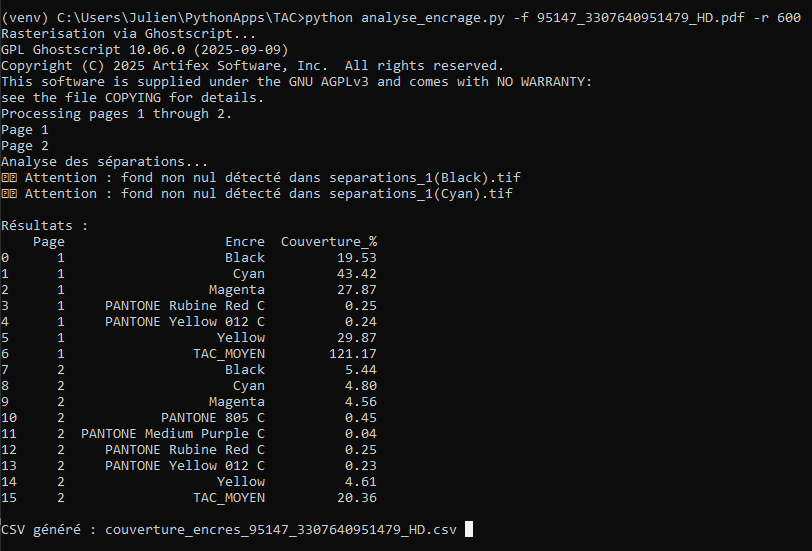
On observe ici que les tons direct/spots sont pris en compte dans le calcul, il conviendra de les ignorer si ces encres concernent (comme ici) des repères de rainage, de coupe ou de marge de sécurité 😉.
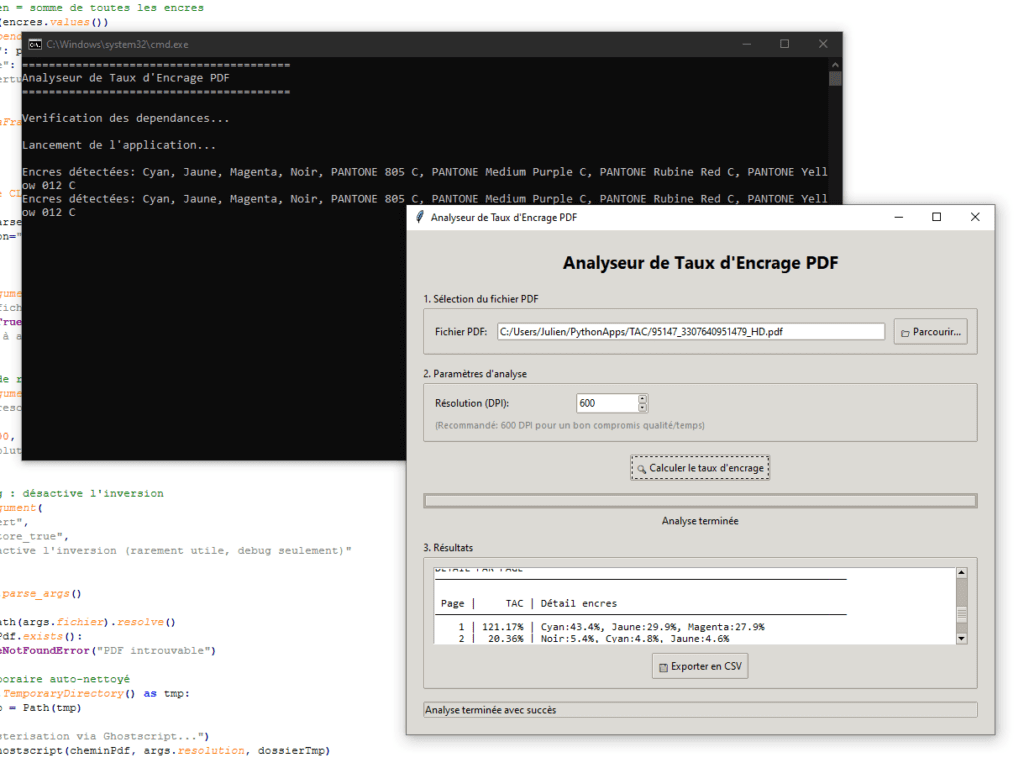
Pour aller plus loin et simplifier le process, on demande un coup de pouce à Claude pour obtenir un petit programme avec une interface graphique :
- l’utilisateur choisit un PDF
- il indique une résolution de travail
- le programme génère les séparations
- calcule les couvertures moyennes
- exporte un CSV exploitable dans Excel
L’intérêt n’est pas seulement le confort : c’est surtout la reproductibilité. On peut rejouer l’analyse à l’identique, versionner les résultats, et intégrer ça à un flux d’éco-conception.
Conclusion
La mesure “au point” reste utile pour diagnostiquer une zone précise (par exemple une surcharge locale pouvant causer du maculage par superposition).
Mais si l’objectif est de parler d’éco-encrage et de comparer des designs, il est utile de disposer d’un indicateur global, calculé de façon objective sur la surface entière, et qui inclut toutes les encres, y compris les tons directs. Cette méthode est un outil complémentaire dans une démarche d’éco-conception.
Pour les actions d’optimisations, le guide de CITEO présente des exemples réels par remplacement de benday CMJN par des tons directs (suppression d’une couche) ou une présence accrue de réserve blanche (augmentation du corps typographique en réserve). Le guide est très bien fait et permet aussi d’estimer l’épaisseur et le poids d’encre selon le procédé d’impression. Il est rédigé par Fabrice Peltier et édité par CITEO.
